















Готово!
Скоро материал придет на указанную электронную почту. Также подписывайте на нас в Facebook
Ok
От Docker Compose к кластеру: миграция 20+ контейнерного монолита в трехузловой Swarm

{kind=link}
Я работаю DevOps-инженером в команде разработки продукта Колибри-АРМ, аналога Microsoft SCCM, покрывающего потребности в импортозамещении ПО для управления парком АРМ. В данной статье будет описан кейс решения задачи по обеспечению высокой доступности продукта – она будет по большей части описывать перенос непосредственно функциональности, и тут не будут рассматриваться такие аспекты как безопасность кластера и приложения внутри.
С ростом количества клиентов, внедряющих наш продукт, начали появляться конкретные запросы: «Нам нужна отказоустойчивость или высокая доступность. И гарантия, что в случае сбоев ваш продукт будет работать». К решению задачи обеспечения высокой доступности мы с командой подошли со следующими вводными:
-
— Наш продукт был только недавно переведен на контейнеры. До этого строился на основе systemd-сервисов.
-
— Из-за решения проблем свежеиспеченной контейнеризованной версии состав сервисов часто менялся.
Вводная
Выбор инструментария
Исходя из эти данных был проведен небольшой сравнительный анализ. По большей части сравнивался входной порог в технологии оркестрации – процесса автоматизации развертывания, масштабирования и управления жизненным циклом контейнеров в кластерной системе, который позволяет эффективно управлять приложениями без ручного контроля.
Порог входа в технологию без переучивания и длительного погружения для того, чтобы выйти на нормальный уровень поддержки продукта, оказался Docker Swarm. На этом моменте меня и команду совершенно не смущало то, что в большом количестве мест говорят: "Docker Swarm хорошо подходит для маленьких проектов, а kubernetes существует в стольких реализациях - бери и пользуйся". Все эти предостережения были отклонены с комментарием: "У нас не настолько требовательный продукт, чтобы крутить его на HighLoad-инфраструктуре!".
Во время поиска информации я не нашел материалы, которые опишут практику, как перенести существующее приложение в кластер, обеспечивая его высокую доступность. Поэтому решил написать данную статью, взяв за основу наш кейс. P.S. Если вы натыкались на книги или статьи по этой теме – посоветуйте, буду благодарен!
Также при выборе инструментария необходимо было выбрать такое решение, которое выполнит задачу обеспечения высокой доступности и при этом не расширит сильно пул поддерживаемых нашей командой сервисов. Мы поняли: нам нужно было сделать решение таким, чтобы большая часть команды сопровождения могла без сильного переобучения продолжать поддержку решения.
Так как мы уже пошли по пути Docker Compose, после небольшого сравнения инструментов стало ясно, что логично было бы продолжить эту идею и использовать встроенный в Docker функционал по объединению виртуальных машин в Swarm-кластер. При этом мы не вводим принципиально другой инструментарий и можем обойтись простой передачей компетенций, связанных с углублением в Swarm.
Помимо непосредственно инструмента оркестрации еще были подняты вопросы по файловой системе, и единой точке входа в кластер. Подход остался примерно тот же – берем надежные инструменты, которые максимально просты в установке и настройке, а также просты для передачи компетенций по их поддержке.
Решение: kubernetes = overkill?
Итак, в ходе совещаний не раз возникала аналогия что использовать kubernetes как оркестратор для нашего продукта. Это как забивать гвозди телескопом – можно, но как будто бы что-то неправильно… А для поддержки kubernetes нужно изучить, как он работает со стороны администратора и со стороны пользователя. Научиться писать большое количество манифестов для внедрения уже новых сервисов в наш продукт. В этом плане может помочь kompose, однако он не даст экспертизы по kubernes – скорее, просто слегка облегчит вход. Как быть?
Три ноды – минимальный кластер из трех управляющих серверов
Для обеспечения отказоустойчивости и согласования кластера Docker Swarm использует алгоритм RAFT-консенсуса. Это работает из-за того что при внутренних голосованиях достигается кворум т.е. количество нод-менеджеров равное (N/2)+1, где N – это количество голосующих нод. Этот алгоритм позволяет иметь одну ноду-лидера в кластере, которая принимает решения.
При таком количестве из-за особенностей работы алгоритма-RAFT, в случае, когда одна из нод выходит из строя, оставшиеся члены кластера поддерживают рабочее состояние кластера, и планировщик перераспределяет нагрузку исходя из изменившегося состояния. В случае, если выбывшая нода была лидером кластера, оставшиеся ноды начинают раунд голосования для определения нового лидера.
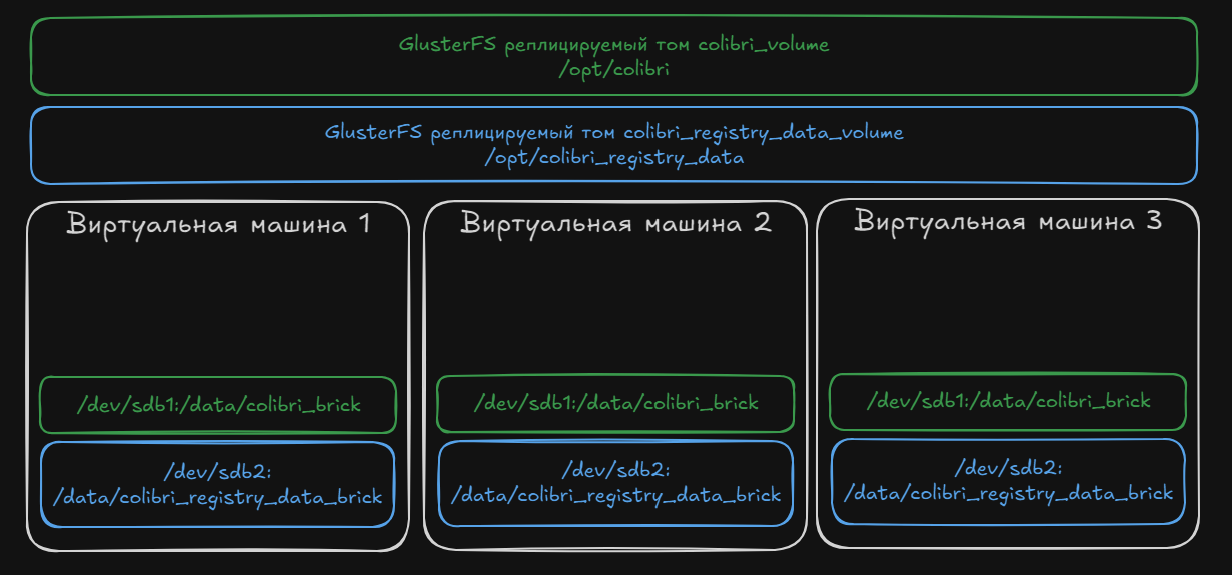
Единая файловая система для приложения за счет GlusterFS
Теперь перейдем к файловой системе – стояла задача сделать 3 ноды, которые могут взаимозаменяться. Для этого было нужно, чтобы файлы приложения были синхронизированы между нодами.
Мы рассматривали разные варианты:
-
Один – с NFS-ресурсами, которые синхронизируются с помощью rsync-скрипта, и где один ресурс подключался ко всем нодам. Этот вариант был отвергнут из-за большого количества скриптов, которые нам нужно было сделать, чтобы обеспечить надежность метода.
-
Еще одним из вариантов было вынесение хранилища на отдельный сервер. В случае падения одной из нод это дало бы результат, и особенности реализации программного блочного хранилища тоже имели место быть, иными словами – программный iSCSI требует ручного управления блокировками, а это уже сильно усложняет реализацию. И тут вопрос сервера хранилища все еще остался не покрыт. Отдельный сервер сам по себе не отвечал требованиям к высокой доступности.
-
Отдельный аппаратный storage с общим LUN, подключенным ко всем нодам. Это идеальный сценарий, но, как и все идеальное – далекое от реальной жизни. Чаще всего, жизненный цикл использования Колибри-АРМ начинается с пилотного внедрения в некотором тестовом контуре, где подобного оборудования банально нет. Но если вы внедряете сразу в продуктивный контур – лучше так.
В итоге перебор вариантов сошелся к распределенным файловым системам. Сравнивали по большей части Ceph и GlusterFS. Lustre не рассматривали из-за сильной ориентированности на очень большие хранилища. Основным критерием выбора по большей части был тот же – низкий уровень входа для команды поддержки.
По итогу небольшого исследования уровень входа ниже оказался у GlusterFS, условно установил, запустил, создал том, примонтировал. Здесь не будет глубокой аналитики на тему плюсов и минусов GlusterFS и Ceph. Ниже приведена краткая таблица по сравнению.

К тому же, сразу из коробки GlusterFS предлагает возможность создать реплицируемый том, что подходит к нашей концепции заменяемых нод.
Стоит отметить, что для крупных и серьезных внедрений мы рекомендуем не использовать GlusterFS, и вместо этого отдавать предпочтение зрелым аппаратным решениям хранения данных. Это связано с тем, что GlusterFS является менее стабильной реализацией, которая может не соответствовать высоким требованиям к надежности и производительности в больших кластерах. Поэтому материал больше ориентирован на небольшие кластеры с умеренными требованиями, где простота установки и поддержки важнее максимально высокой отказоустойчивости.
Создание единой точки входа с помощью keepalived
После того как собрали кластер Docker Swarm и настроили файловое хранилище для контента контейнеров, необходимо как-то обращаться к приложению, развернутому в кластере. Сам по себе Docker Swarm имеет интересную особенность: каждая менеджер-нода кластера является точкой входа в кластер. Поэтому получить доступ к приложению можно, обратившись к любой ноде кластера. Мы выделили отдельный ip-адрес под виртуальный и настроили keepalived для выдачи этого виртуального ip-адреса одной из нод.
Ход работ
Стадия 0. Ничего не понятно, но очень интересно. Определение плана работ
Определившись с инструментами, начали прорабатывать то, как, собственно, перетащить наш по сути монолит, недавно разделенный на контейнеры в кластер для выполнения поставленной задачи. Прежде всего нужно настроить сам кластер, куда будем развертывать приложение. Для начала работы хватит GlusterFS и Docker Swarm.
После того как развернули основу, на которой будем размещать приложение, нужно попробовать развернуть наше приложение как мы это делаем обычно – с использованием нашего инсталлятора. Также стоит пока привязать все контейнеры к одной ноде. Это нужно для того, чтобы в дальнейшем по одному сервису отлаживать все проблемы, связанные с сетью и распределением контейнеров по кластеру. Следующим этапом мы начинаем убирать привязку к одной ноде по одному сервису и смотреть взаимодействие.
По завершению переноса всех сервисов важным продолжающим шагом будет описать что изменилось в конфигурации сервисов мононоды – для того, чтобы сформировать принцип, по которому можно будет переписывать уже новые сервисы под Swarm-развертывание. После этих шагов можно приступить к полноценному QA-тестированию.
А завершив тестирование и исправив все найденные проблемы, приступаем к завершающему эту итерацию шагу – написанию скриптов для облегчения развертывания кластера и скриптов для помощи существующему установщику и развертыванию в кластере продукта.
Продолжение читайте на Хабре...
Будьте в курсе новостей
Подпишитесь на рассылку и будьте в курсе наших последних новостей